Revolutionizing JEE Practice with AI-Driven Adaptive Learning
TL;DR
Concept Master leverages an AI-driven pipeline to personalize JEE Mains + Advanced practice. By continuously learning student embeddings from their question attempts, the system predicts the probability of a student solving a question. This enables rapid assessment of student levels, creates personalized difficulty maps, and recommends questions with maximum learning impact, optimizing the practice experience for every student.
The Core AI-Driven Practice Pipeline
Concept Master's adaptive learning system is built around a sophisticated AI pipeline designed to optimize the JEE practice experience. The process unfolds in a continuous loop, adapting to each student's evolving knowledge state:
- Student Engagement: Students begin by selecting a subject, topic, or subtopic they wish to practice. They then proceed to solve questions one-by-one, providing their attempts and answers to the system.
- Continuous Embedding Learning: As students interact with the platform, the system continuously learns and updates student embeddings. These embeddings are dense vector representations that capture a student's latent knowledge, skills, and learning patterns based on their historical performance and interactions with various questions. This process is analogous to how word embeddings capture semantic meanings of words, but here, they represent a student's cognitive profile.
- Predictive Modeling: A machine learning model is trained and continuously updated using these student embeddings and question characteristics. The primary objective of this model is to predict the probability P(student solves a question), yielding a score between 0 and 1. This probability signifies the likelihood of a given student correctly answering a specific question.
Why This is Useful: Three Pillars of Personalized Learning
The AI-driven pipeline in Concept Master translates directly into three significant benefits, fundamentally transforming how students prepare for JEE:
1. Rapid Assessment of Student Proficiency
Benefit: The system can quickly gauge the proficiency level of a student after just a few question attempts.
How the Model Enables It: By analyzing the initial student embeddings and their performance on a small set of diagnostic questions, the predictive model can rapidly converge on an estimated P(student solves a question) for a wide range of problems. This allows for an almost instantaneous understanding of a student's strengths and weaknesses, eliminating the need for lengthy pre-tests or manual evaluations.
2. Personalized Difficulty Mapping
Benefit: Each student receives a unique personalized difficulty map, identifying which questions are likely solvable and which are not for them.
How the Model Enables It: The predictive model, using the student embeddings, can calculate P(student solves a question) for any question in the database. This generates a dynamic, granular difficulty profile for each student. A question that is easy for one student might be challenging for another, and the system accurately reflects these individual differences. This personalized map guides students to practice at their optimal challenge level, preventing frustration from overly difficult problems and boredom from overly simple ones.
3. Recommendation for Maximum Learning Impact
Benefit: The system intelligently chooses the next question to recommend, maximizing its learning impact (information gain / expected improvement).
How the Model Enables It: This is where the adaptive nature of Concept Master truly shines. After each question attempt, the student's embeddings are updated, and the model recalculates their knowledge state. The system then employs strategies based on information gain or expected improvement to select the next question. Information gain refers to selecting a question that, when answered, will provide the most significant update to the student's knowledge model. Expected improvement focuses on questions that are most likely to move the student towards mastery, considering their current proficiency and the question's difficulty. This ensures that every question presented is highly relevant and contributes maximally to the student's learning progression.
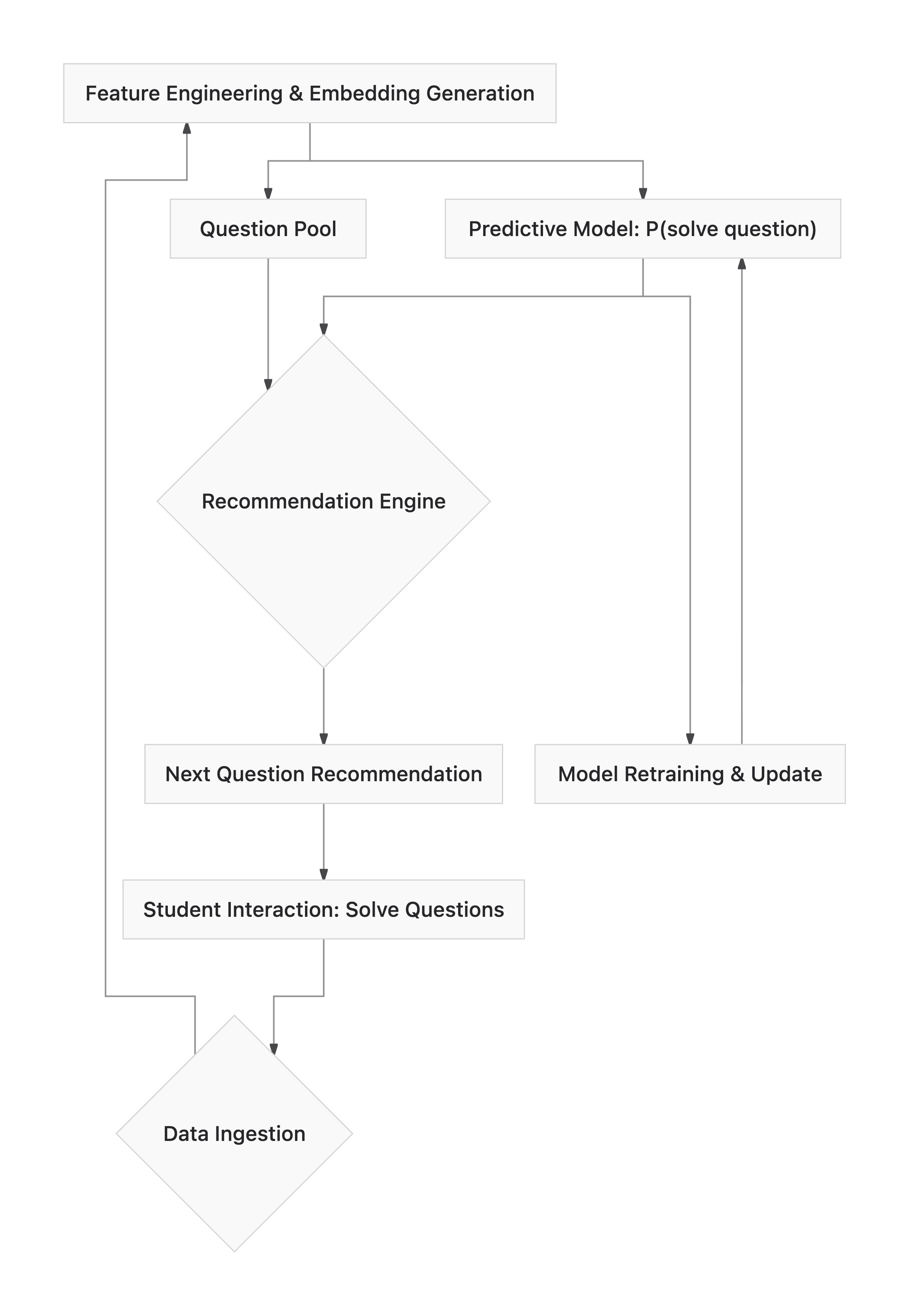
Proposed End-to-End Architecture/Pipeline
An effective AI-driven JEE practice pipeline requires a robust architecture that handles data flow, model training, and real-time inference. Here's a high-level overview:
- Data Ingestion Layer: Collects student interaction data (question attempts, answers, time taken, hints used) and question metadata (topic, subtopic, difficulty, type).
- Feature Engineering & Embedding Generation: Raw student interaction data is processed to create features. Student embeddings are generated and continuously updated using techniques like recurrent neural networks (RNNs) or transformer-based models, which are well-suited for sequential data like student response histories. Question embeddings are also generated, representing the characteristics and difficulty of each question.
- Predictive Model (Knowledge Tracing): A deep learning model (e.g., Deep Knowledge Tracing - DKT, or a variant of Item Response Theory - IRT combined with deep learning) takes student and question embeddings as input. Its output is P(student solves a question).
- Recommendation Engine: Based on the predictive model's output and learning objectives, this engine uses algorithms (e.g., based on information gain, expected improvement, or reinforcement learning) to select the optimal next question for the student.
- Feedback Loop & Model Retraining: Student responses to recommended questions feed back into the data ingestion layer, continuously updating student embeddings and triggering periodic retraining or fine-tuning of the predictive model. This ensures the system remains adaptive and accurate over time.
Modeling Approach: A High-Level View
The core of Concept Master's intelligence lies in its predictive model, which is a form of Knowledge Tracing. Unlike traditional methods that might rely on static difficulty ratings, our approach dynamically models each student's knowledge state.
At its heart, the model learns to map a student's history of interactions (which questions they answered correctly or incorrectly) to a latent representation (the student embedding). When a new question is presented, the model combines the student's current embedding with the question's embedding to predict the probability of a correct answer. This is often achieved using neural networks, which can capture complex, non-linear relationships between student history, question properties, and performance.
The continuous learning of student embeddings is crucial. As a student practices, their knowledge evolves. The embeddings are designed to reflect this evolution, making the predictions highly personalized and adaptive. The model doesn't just track whether a student knows a concept; it estimates how well they know it and how that knowledge changes over time.
Evaluation: Ensuring Effectiveness and Fairness
Rigorous evaluation is essential to ensure the AI pipeline is effective and fair. We employ both offline and online metrics:
Offline Metrics
Offline evaluation involves testing the predictive model on historical student data. Key metrics include:
- Area Under the Curve (AUC): Measures the model's ability to distinguish between correct and incorrect answers.
- Accuracy/Precision/Recall: Standard classification metrics to assess prediction quality.
- Log Loss: Quantifies the uncertainty of the predictions.
These metrics help us compare different model architectures and hyperparameter settings before deploying them in a live environment.
Online A/B Style Signals
Online evaluation involves deploying different versions of the recommendation engine to subsets of live users and monitoring their performance. Key signals include:
- Learning Gain: Measuring the improvement in student performance over time for students in different experimental groups.
- Engagement Metrics: Tracking metrics like time spent on platform, number of questions attempted, and completion rates.
- Student Satisfaction: Gathering direct feedback from students regarding the helpfulness and relevance of recommendations.
This A/B testing approach allows us to validate the real-world impact of our AI system and continuously iterate for improvement.
Beyond the Core: Comparisons and Considerations
Classical Adaptive Testing vs. Knowledge Tracing
Traditional adaptive testing often relies on Item Response Theory (IRT), which models the probability of a correct answer based on a student's ability and a question's difficulty and discrimination parameters. While effective, IRT typically assumes a static student ability over a test session and doesn't explicitly model the learning process or how knowledge evolves. Concept Master's approach, rooted in Knowledge Tracing, directly addresses this by continuously updating student knowledge states, making it more suitable for ongoing practice and learning environments rather than just assessment.
Privacy and Ethics
Given the sensitive nature of student data, privacy and ethical considerations are paramount. Concept Master adheres to strict data privacy protocols, anonymizing data where possible and ensuring secure storage. Ethically, the system is designed to promote equitable learning opportunities, avoiding biases that could disadvantage certain student groups. Regular audits of the AI model for fairness and transparency are conducted to ensure responsible AI deployment.
Conclusion
Concept Master's AI-driven JEE practice pipeline represents a significant leap forward in personalized education. By leveraging advanced machine learning techniques to understand and adapt to each student's unique learning journey, we empower them to achieve their full potential in the highly competitive JEE examinations. This intelligent system not only makes practice more efficient but also more engaging and effective, truly mastering concepts one question at a time.